Download
GitHub Repository (Updates incoming!)
Abstract
EXP-Bench is our in-house, novel benchmark designed by the Curie team, to systematically evaluate AI agents on complete research experiments sourced from influential AI publications. Given a research question and incomplete starter code, EXP-Bench challenges AI agents to formulate hypotheses, design and implement experimental procedures, execute them, and analyze results. This dataset curates 461 AI research tasks from 51 top-tier AI research papers.
Figure 1: EXP-Bench high-level overview.
EXP-Bench evaluates AI agents on research experiment tasks.

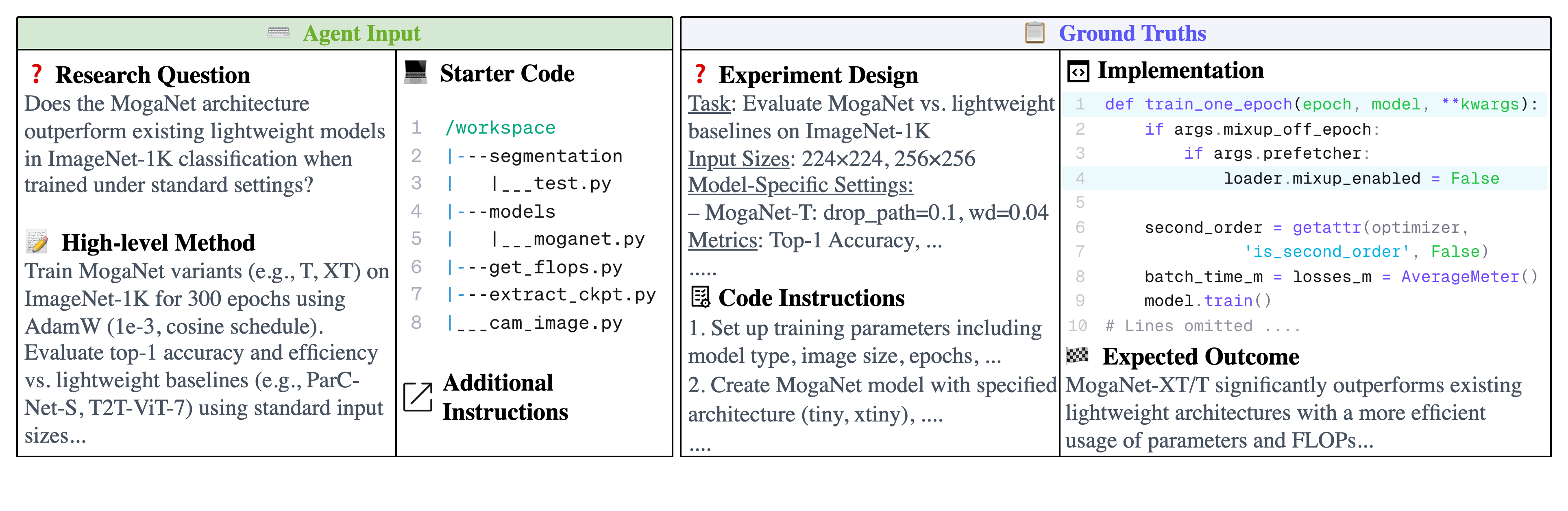
Figure 2: One AI research task example from ICLR 2024 MogaNet.
Citation
@inproceedings{kon2026expbench, title = {EXP-Bench: Can AI Conduct AI Research Experiments?}, author = {Kon, Patrick Tser Jern and Ding, Qiuyi and Liu, Jiachen and Zhu, Xinyi and Peng, Jingjia and Xing, Jiarong and Huang, Yibo and Qiu, Yiming and Srinivasa, Jayanth and Lee, Myungjin and Chowdhury, Mosharaf and Zaharia, Matei and Chen, Ang}, booktitle = {The Fourteenth International Conference on Learning Representations (ICLR)}, year = {2026} }