Download
Abstract
Cloud infrastructure is the cornerstone of the modern IT industry. However, managing this infrastructure effectively requires considerable manual effort from the DevOps engineering team. We make a case for developing AI agents powered by large language models (LLMs) to automate cloud infrastructure management tasks. In a preliminary study, we investigate the potential for AI agents to use different cloud/user interfaces such as software development kits (SDK), command line interfaces (CLI), Infrastructure-as-Code (IaC) platforms, and web portals. We report takeaways on their effectiveness on different management tasks, and identify research challenges and potential solutions.
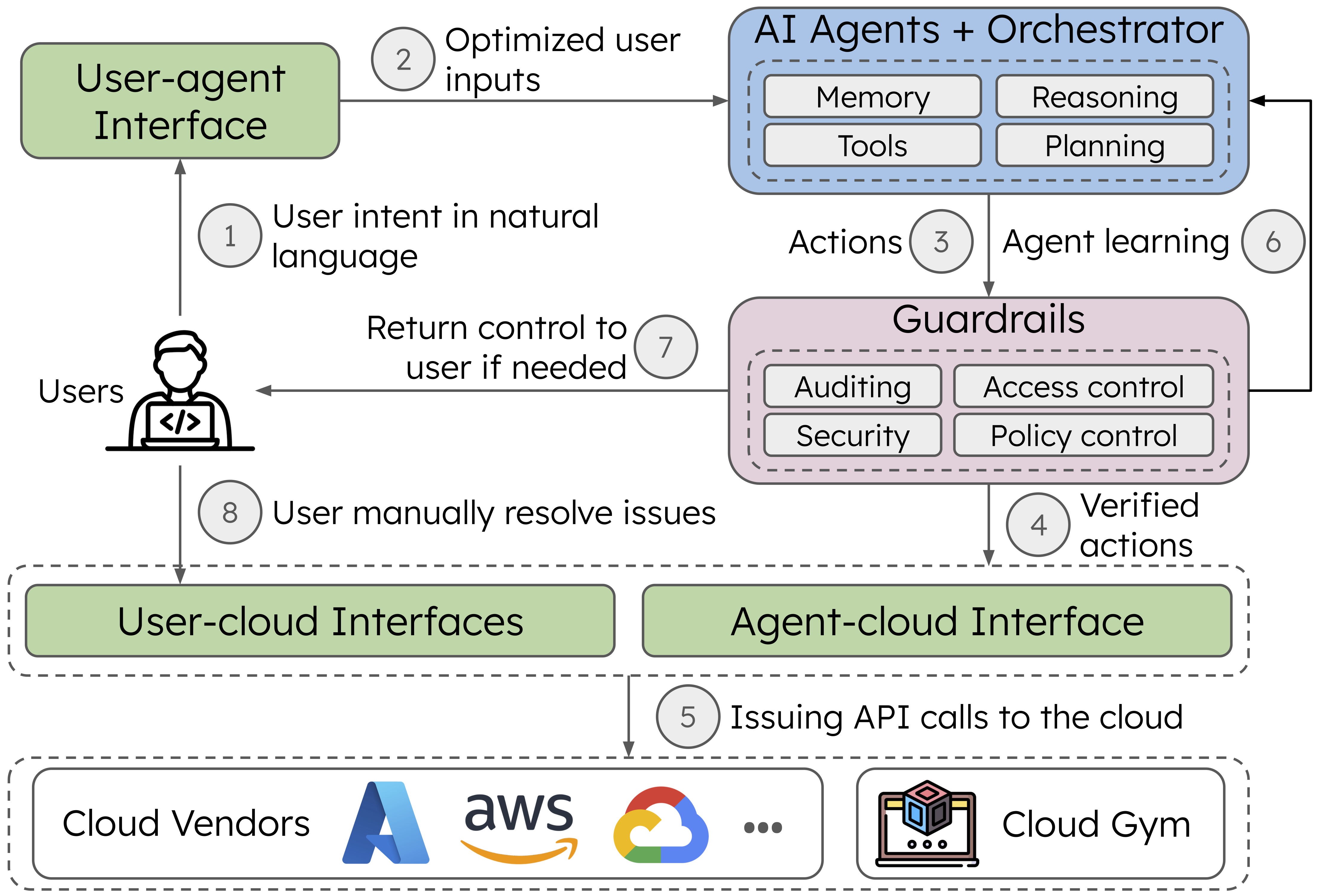
Figure 1: Envisioned agentic system architecture and workflow for cloud infrastructure management.
Citation
@article{yang2025cloudagents, title = {Cloud Infrastructure Management in the Age of AI Agents}, author = {Yang, Zhenning and Bhatnagar, Archit and Qiu, Yiming and Miao, Tongyuan and Kon, Patrick Tser Jern and Xiao, Yunming and Huang, Yibo and Casado, Martin and Chen, Ang}, journal = {ACM SIGOPS Operating Systems Review}, volume = {59}, number = {1}, pages = {1–8}, year = {2025}, doi = {10.1145/3759441.3759443} }